Unfortunately, with the vast amount of space hard drives have these days, it can be months or even years before our bad habits catch up to us.
Our computers become sluggish and unresponsive, leaving us with a daunting task of finding the clutter. A massive clutter.
So what do you do? Well, the average PC guru will launch the Windows Disk Cleanup tool, and honestly, it's a fair tool to run on a regular basis for general purpose cleaning.
It clears things like temporary internet files, memory dumps, and other junk your system holds onto longer than it should. You can launch it by pressing Win + R, typing cleanmgr, and hitting Enter.
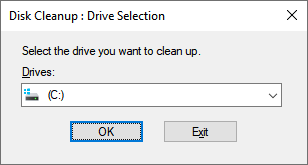
Select the drive, check the boxes for the files you want to clean up, like system files, logs, or old updates, and click OK. Simple enough.
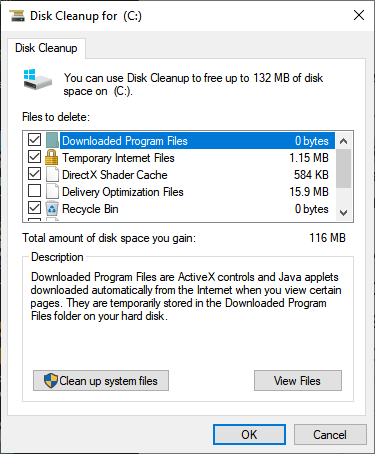
However, when you need to do a thorough cleaning, there’s a tool called WinDirStat that really shines.
This tool does a fantastic job of showing you exactly where your data is stored by percentage. Even better, it can locate duplicate files across your drive, even if they have different file names.
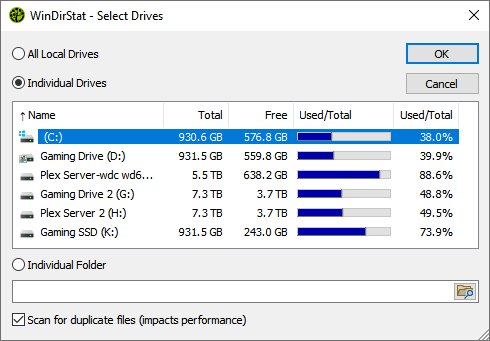
First, you're going to want to select the drive to examine. If you want to also search for duplicate files, be sure to check the box below that enables duplicate detection.
Next, you’ll see a screen that maps out your drive’s file structure along with all its contents. At the top, folders are listed in size order so you can see which ones are using the most space.
Down below, there’s a tree map with a colorful grid where each block represents a file, and the size of the block tells you how much space it’s using.
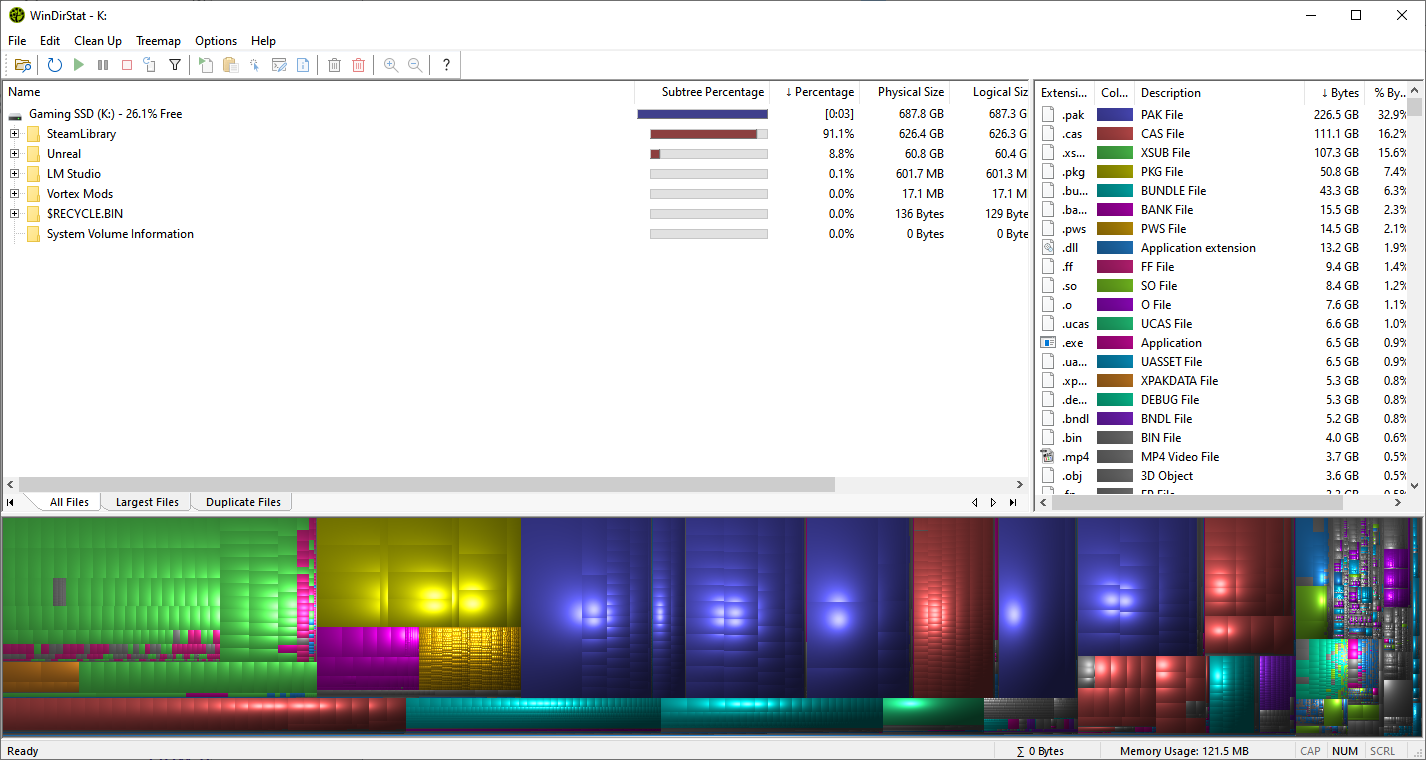
You can click through folders and locate your largest files to begin the decluttering process. As you dig deeper, the percentages will adjust, helping you pinpoint the stuff that's eating up space. It’s much easier than browsing through Explorer trying to guess what's taking up room.
At the bottom of the window, you'll see a visual graph of the files and their types.
There’s a color legend on the right to help you figure out what kind of data you’re looking at such as videos, archives, executables, and so on.
Right above the graph, there's a tab to switch to a Duplicates view, which is super handy.
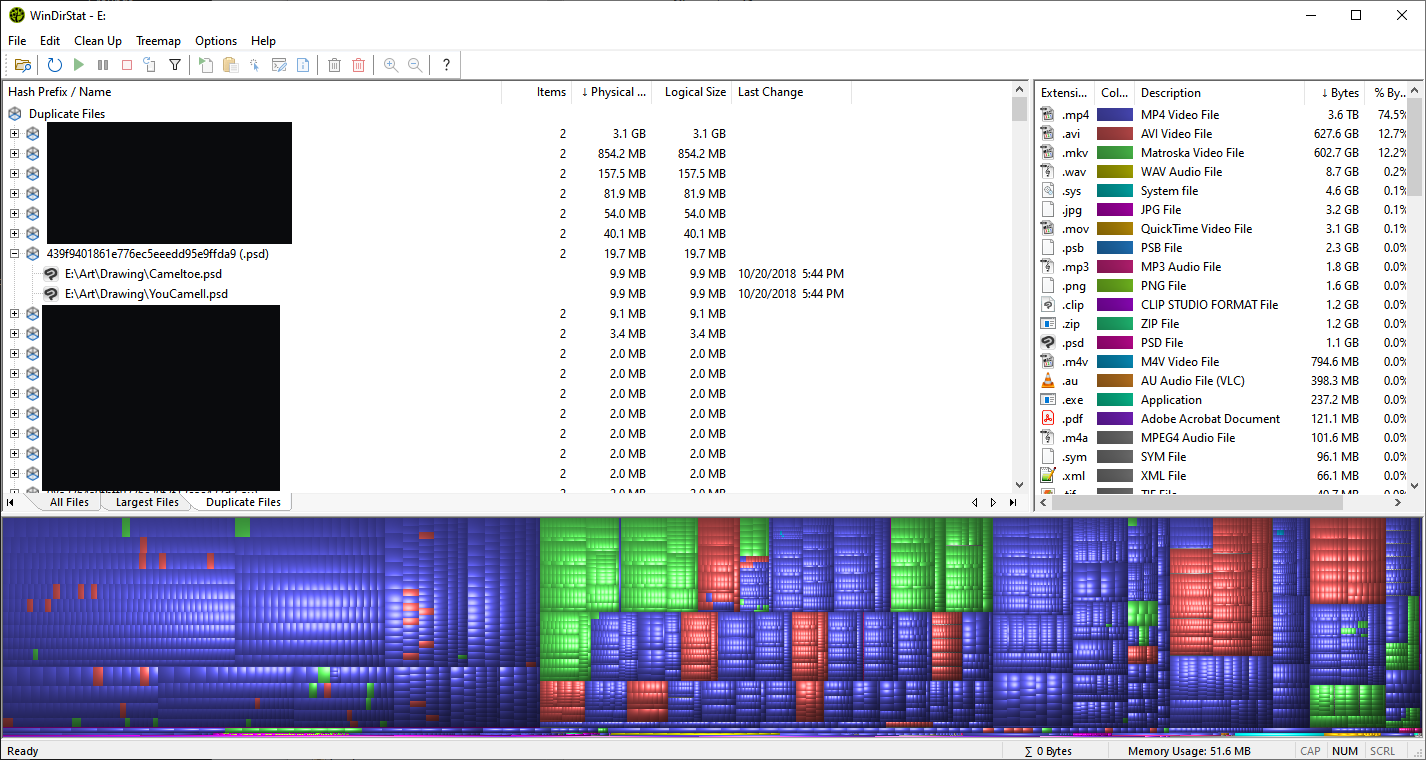
In the screenshot above, you can see duplicate files listed. These are found by comparing each file's hash, which is basically a digital fingerprint that's unique to the file’s content. This means even if the name is different or it’s in a different folder, it’ll still detect that it’s a clone.
The example shown includes one of my old art pieces from a few years ago.
Here it is below, for those who are curious.